IdP operators: consider using MDQ (metadata query)
Configuring your self-hosted IdP to use MDQ (metadata query) has three key benefits:
- a reduced memory footprint
- mitigation against a class of disruptive errors as the size of metadata increases
- robustness against problematic metadata.
Half of the IdPs in the UK federation use MDQ already. The UK federation team urge the remaining IdP operators to consider using MDQ instead of the classical model of metadata aggregates.
Problems with metadata aggregates
Traditionally, entities have obtained information about other entities by regularly downloading a single metadata file, which we call our metadata aggregate, containing information about all possible entities they could interoperate with. This aggregate contains information like organization names, logos, web service endpoints, and public keys. It provides all the technical information that an entity needs to operate in the UK federation.
The integrity of this aggregate is provided by a digital signature generated using the UK federation’s signing key, calculated over the whole file. Entities which use the UK federation metadata must check this signature when they download a new version of the file. You’ll find instructions from your IdP vendor how to do that. Note that, because this digital signature is calculated over the whole file, metadata consumers must have sufficient RAM to process (download, unpack, verify the signature) the whole metadata file.
As participation in the UK federation has grown, our metadata file contains information on over 8,000 entities and it has increased in size to over 70 MB. We see the upward trend continuing, primarily through our use of the eduGAIN interfederation service.
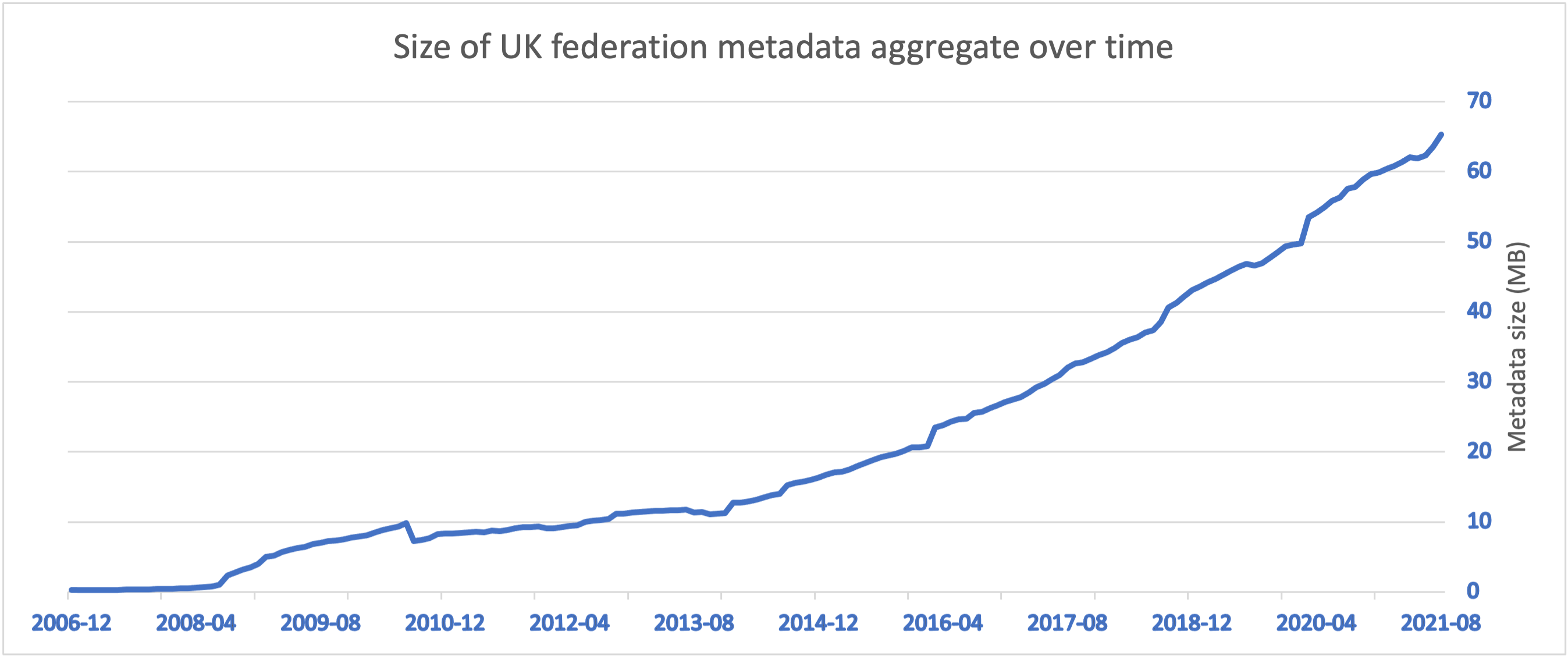
Problems with large metadata size have become apparent:
-
Recommendations for memory when commissioning a new IdP continue to increase. Due to the variety of ways to configure an IdP (choice of operating system; jetty or tomcat as a web servlet container; with httpd terminating the TLS connections or not) it’s difficult to make a definitive statement.
-
When an IdP cannot consume and verify a large aggregate it typically does not fail totally. An IdP may appear to be working (in the sense that it displays a login page) but the IdP stops being able to interoperate. Such failures are usually due to out-of-memory in the metadata refresh process. They typically occur in the early evening in the UK. They’re not because of system upgrades. And because the IdP is part of an organization’s identity management system, it’s difficult to isolate and rectify the problem.
-
A new aggregate must be generated if any entity updates its metadata. Entities download the new aggregate, even if they do not interoperate with any of the entities that have changed.
-
The federation operator has significant network load. When 2000 entities download a 70MB file, it generates 140 GB network traffic.
We have already deployed features to alleviate some of these problems. For example we support HTTP conditional GET so that clients only download metadata when it has changed. We also support compressed metadata through the Accept-Encoding header in the request. Other federations have taken the approach of splitting metadata into separate aggregates for IdPs and for SPs. These approaches are, at best, temporary measures.
Introducing MDQ
Another approach exists. MDQ is a mechanism that allows entities to request only the metadata they need, as they need it. In the MDQ model, you configure your entity to request metadata from the UK federation MDQ service. IdPs using MDQ request metadata for individual SPs as and when required, instead of periodically downloading the whole aggregate file.
Benefits and risks for IdP operators
The major benefit to is that you require a much lower memory footprint for your IdP. We have anecdotal evidence that a Shibboleth IdP can run with a Java heap size of 512MB, compared to the UK federation recommendation to use a minimum heap size of 2 GB when consuming the current aggregate.
Other benefits are:
-
IdP start-up time is typically faster.
-
By downloading only the metadata that you need, you gain robustness against problematic metadata in the whole aggregate.
-
Disruptive and difficult to diagnose out-of-memory errors are much less likely.
A risk specific to IdP operators is that your existing attribute release policies may implicitly reference a metadata aggregate, so we recommend that you review these before moving to MDQ.
Another risk is that you move from a situation where your entity downloads metadata in the background — which allows retries if the metadata server is unavailable — to a situation where you query metadata just-in-time.
Several mitigations have been developed to reduce the risk of MDQ service unavailability:
-
Metadata has a validity period. In normal operation, the validity interval used for UK federation metadata aggregates is 14 days. This may be varied in either direction for operational reasons, but until further notice will never be less than 7 days nor more than 28 days.
-
On the client side, caching is built into Shibboleth IdPs and presumably other IdP software.
Robustness of the MDQ service
The service is composed of multiple redundant webservers with geographical resilience. This means that the fundamental metric we use, that of service uptime, has been measured at 100% since piloting in 2017.
We must also consider the response times for the service, to decide whether the service is usable in practice. But what would be a good figure? Obtaining metadata for an entity is one small part of the overall flow, and a part that’s typically not needed for every login due to caching of metadata at the IdP. Nonetheless, a good response time is needed. InCommon’s Per Entity Metadata Working Group recommended that response times should be less than 200ms. That working group didn’t show their calculations, but it’s certainly a target to aim for.
If we peer more closely at the MDQ service, we’ll see it’s in two distinct parts: generation of signed entity metadata, and distribution of it. A simple model of a MDQ service would be to sign metadata when it is requested. However this would require expensive cryptographic operations for each metadata request, or some loading of a cache.
The architecture of the UK federation’s service keeps the complexity in the signature generation sub-system and keeps the distribution part as simple as possible. We calculate signatures for all entities on every signing and publishing run, generate the compressed files and hash-based references to entity metadata, and then transfer these files to a number of identical VMs running a simple httpd instance. The identical VMs sit behind a traffic manager and load balancer with geographic resilience.
The following graph shows the response times measured from a London-based monitoring point averaged per day. The average response time is well under 80 ms — far less InCommon’s recommendation of 200ms.
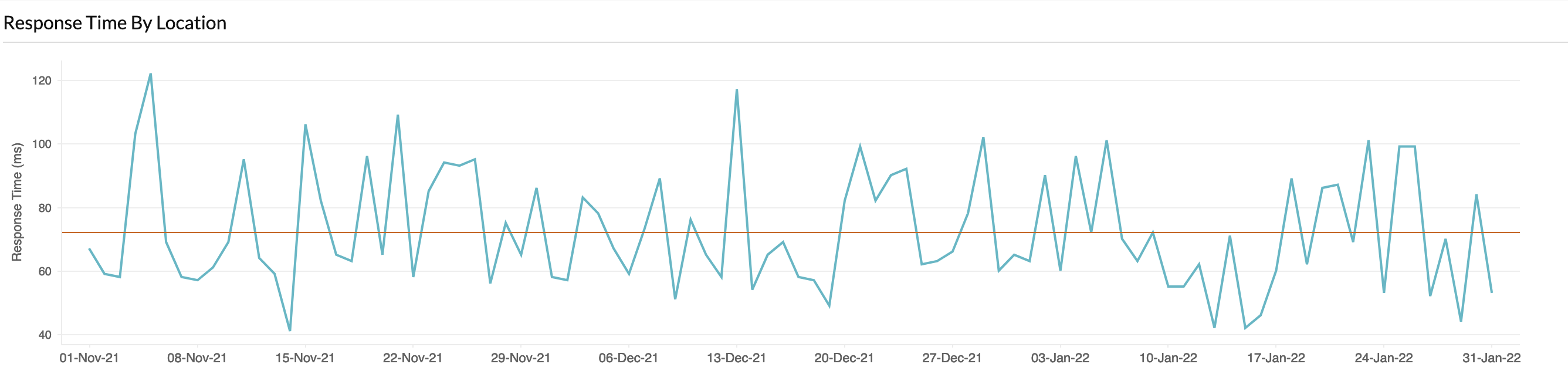
At a finer resolution, there are a few monitoring events (fractions of a percent) which show reponse times of over a second. We currently assume this is not significant for MDQ clients and, since the monitors are not situated on the Janet network like the majority of IdPs in the UK federation, we assume it is an artifact of the monitoring system. Of course, if you think that these isolated events would be a barrier to adoption, please let me know through the UK federation helpdesk at service@ukfederation.org.uk.
Your next actions
If you’re already using the MDQ service, thanks for reading this far! There’s more detail behind the story above. Leave a comment below if you want.
If you’re not using MDQ – and approximately half the Shibboleth IdPs in the UK federation currently do use it — please consider moving to MDQ. You can find the UK federation Federation Technical Specifications about the MDQ service here. You can contact the UK federation helpdesk at service@ukfederation.org.uk if you need assistance.